ProofRAG
ProofRAG started from a practical RAG problem: teams can change a chunker, retriever, reranker, prompt, model, or context-packing strategy, but without a stable evaluation set they are mostly comparing impressions. The hard part is not only running metrics; it is producing a useful golden set from the actual corpus and keeping the evaluation loop repeatable.
The tool packages that loop as both a Python CLI and an agent skill. It reads a corpus, generates and validates corpus-grounded test cases, calls the user's RAG system through HTTP or a Python callable, judges answers with a pinned LLM-as-judge, computes retrieval metrics, and emits a self-contained HTML scorecard.
Project Surface
Package:proofrag
Runtime:Python 3.11+
Core deps:none
Interfaces:CLI, Skill, Action
License:MIT
Evaluation Axes
Retrieval
- Recall@k
- Precision@k
- NDCG@k
- MRR
Generation
- Groundedness
- Correctness
- Completeness
- Citation quality
The Loop
The workflow is intentionally explicit. Each step produces an artifact that can be reviewed, committed, compared, or uploaded by CI.
Artifacts
Golden set:jsonl
Validation:json
Predictions:jsonl
Results:json
Report:html
Command Sequence
proofrag generate --corpus ./docs --out goldenset.jsonl --n 20
proofrag validate --goldenset goldenset.jsonl --corpus ./docs
proofrag run --goldenset goldenset.jsonl --endpoint http://localhost:8000/ask --out predictions.jsonl
proofrag evaluate --goldenset goldenset.jsonl --predictions predictions.jsonl --out results.json
proofrag report --results results.json --out scorecard.html
Golden Set Design
- Questions are generated from the user's own corpus rather than a generic benchmark.
- Difficulty tiers include single-document, multi-document, and unanswerable questions.
- Each gold context preserves source path, chunk id, chunk index, character count, and extension metadata.
- Validation catches duplicate ids/questions, missing contexts, source coverage problems, and corpus fingerprint drift.
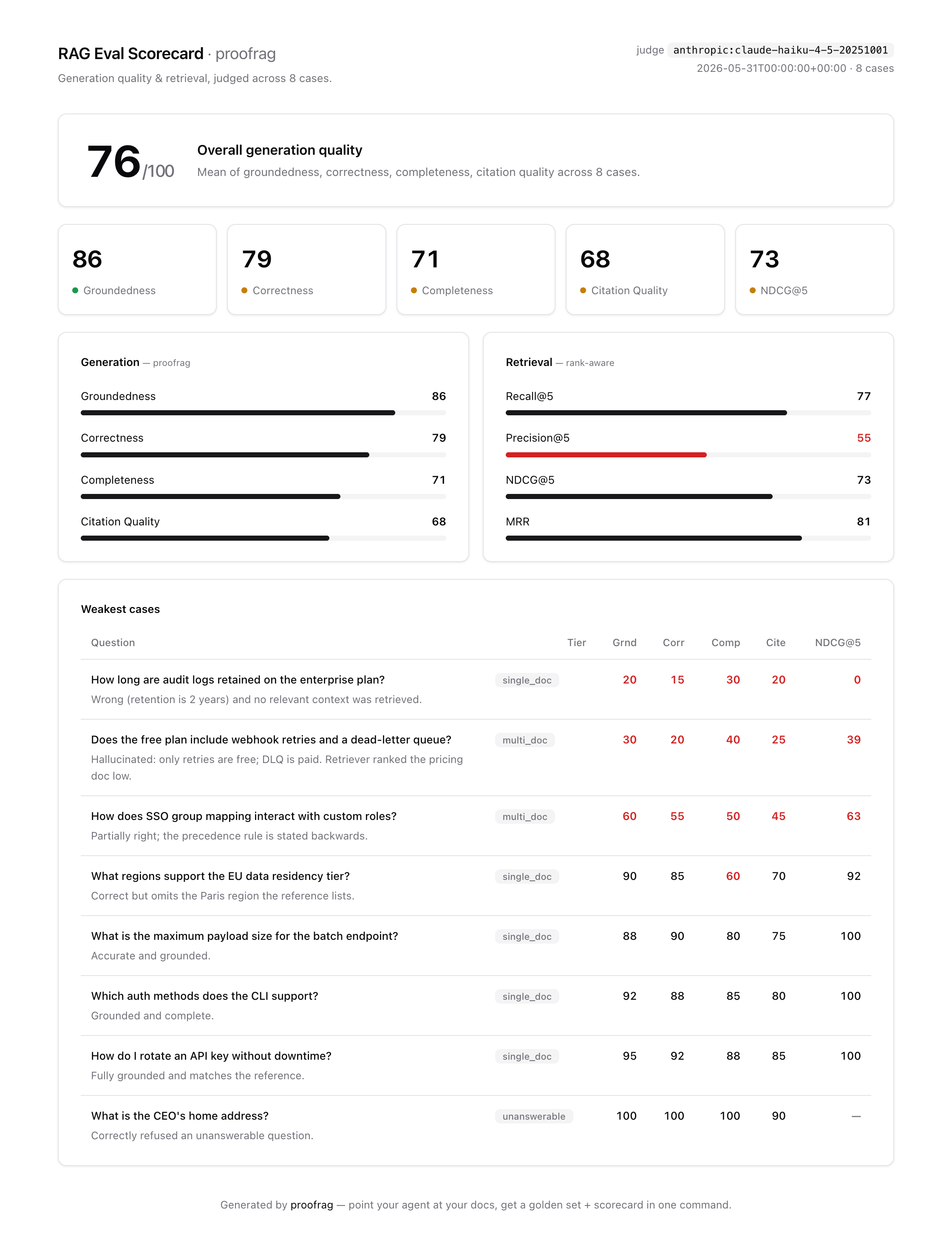
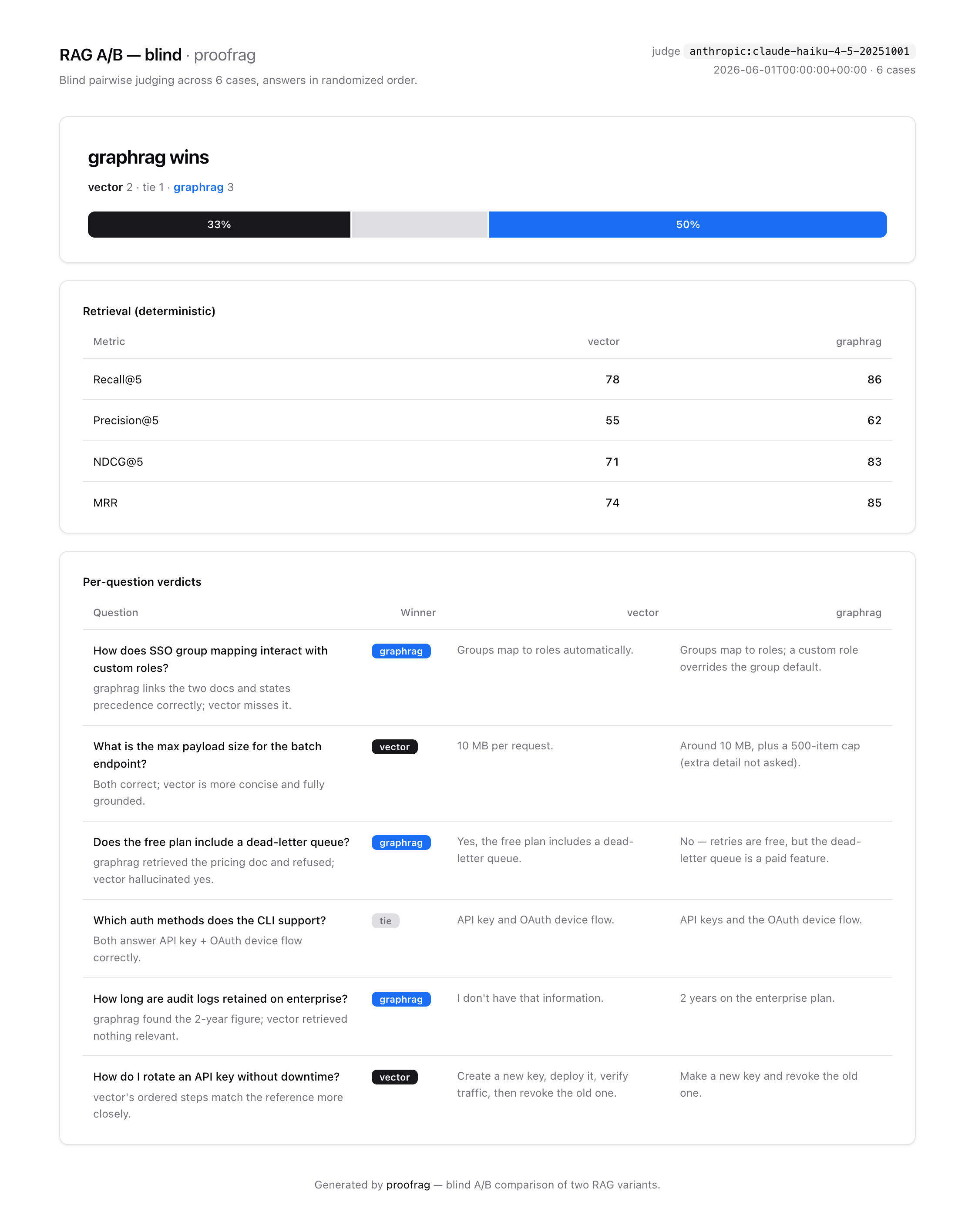
Scorecards
Reports are static HTML files with no external assets. They are designed to be uploaded as CI artifacts, shared with teammates, or opened locally after an agent run.
Evaluation Report
Blind A/B Report
CI Gates
The GitHub Action turns the same CLI into a merge gate. One mode enforces an absolute score floor, while another compares the candidate run against a committed baseline and fails only when a metric regresses beyond a tolerance.
Gate Modes
Absolute:--fail-under
Regression:proofrag diff
Artifacts:html + json
Summary:markdown
Action Example
- uses: unshDee/proofrag@v0
with:
goldenset: eval/goldenset.jsonl
predictions: predictions.jsonl
baseline: eval/baseline.json
fail-under: "0.7"
Agent-Native Surface
ProofRAG also ships as an Agent Skill. The skill does not hide the machinery; it gives an agent a durable procedure for finding a RAG entrypoint, generating or validating test data, running the CLI, and returning the scorecard path.
Providers
Anthropic:extra
OpenAI:extra
Ollama:base url
PDF:optional
Backend Swaps
The default scoring path uses ProofRAG's own pinned LLM judge, but the workflow also supports DeepEval and Ragas as generation-scoring backends. Retrieval metrics, reports, diffing, comparison, and CI gates stay the same when the backend changes.
Related RAG Utilities
I also maintain rag-utils, but I treat it differently from ProofRAG. It is intentionally a collection of scripts I reach for while building RAG systems, not a single product.
rag-utils script collection
- DOCX to chunks with media metadata
- PDF to Markdown conversion
- Offline retrieval evaluation
- Chunk quality scoring
- Overlap merging and semantic dedup
- Context window packing
- Query expansion and HyDE
- SQLite embedding cache
- Span-based RAG tracing
- Hybrid retrieval with reciprocal rank fusion
notes
too bright? click ↝